[Compression/Denoising/Deconvolution/Restoration/Learning][Time-frequency/time-scale/wavelets/filterbanks][Sparsity analysis][Analytical Chemistry data (chromatography/NMR][Geoscience/geophysical processing][Vibration/combustion in engines][Bioinformatics gene network inference & clustering][Seismic data and geological mesh compression][Real-time extrapolation]
Abstract:
A counterexample is any exception to a generalization. Counterexamples are often used in science (and philosophy), as a means to setting boundaries. In mathematics at large, well-chosen counterexamples may bound possible theorems, disprove certain conjectures. This conspectus is (mostly) meant to gather and share counterexample book references (on algebra, analysis, calculus, logic, philosophy, probability, statistics, topology).
Abstract:
The volume of scientific data produced for and by numerical simulation workflows is increasing at an incredible rate. This raises concerns either in computability, interpretability, and sustainability. This is especially noticeable in earth science (geology, meteorology, oceanography, and astronomy), notably with climate studies.
We highlight five main evaluation issues: efficiency, discrepancy, diversity, interpretability, availability.
Among remedies, lossless and lossy compression techniques are becoming popular to better manage dataset volumes. Performance assessment -- with comparative benchmarks -- require open datasets shared under FAIR principles (Findable, Accessible, Interoperable, Reusable), provided in a MWE (Minimal Working Example) with ancillary data for reuse.
We share LUNDIsim, an exemplary faulted geological mesh. It is inspired by the SPE10 comparative Challenge. It is not meant to be compared to the latter for reservoir simulation. It is instead tailored -- with power-of-two dimensions and additional faults -- to both more challenging fluild displacement and upscaling methods, and allowing versatile compression benchmarks.
Enhanced by porosity/permeability datasets, this dataset proposes four distinct subsurface environments. They were primarily designed for flow simulation in porous media. Several consistent resolutions (with HexaShrink multiscale representations) are proposed for each model. We also provide a set of reservoir features for reproducing typical two-phase flow simulations on all LUNDIsim models in a reservoir engineering context. This dataset is chiefly meant for benchmarking and evaluating data size reduction (upscaling) or genuine composite mesh compression algorithms. It is also suitable for other advanced mesh processing workflows in geology and reservoir engineering, from visualization to machine learning.
LUNDIsim meshes are available at https://doi.org/10.5281/zenodo.14641958.
Abstract:
This study focuses on improving the seafloor compliance noise removal method, which relies on estimates of the compliance transfer function frequency response (the deformation of the seafloor under long-period pressure waves). We first propose a new multi-scale deviation analysis of broadband ocean bottom seismometer data to evaluate stationarity properties that are key to the subsequent analysis. We then propose a new approach to removing the compliance noise from the vertical channel data, by stacking daily estimated transfer function frequency responses over a period of time. We also propose an automated transient event detection and data selection method based on a cross-correlation criterion. As an example, we apply the method to data from the Cascadia Initiative (network 7D2011). We find that the spectral extent of long-period forcing waves varies significantly over time so that standard daily transfer function calculation techniques poorly estimate the transfer function frequency response at the lowest frequencies, resulting in poor denoising performance. The proposed method more accurately removes noise at these lower frequencies, especially where coherence is low, reducing the mean deviation of the signal in our test case by 27 % or more. We also show that our calculated transfer functions can be transfered across time periods. The method should allow better estimates of seafloor compliance and help to remove compliance noise at stations with low pressure-acceleration coherence. Our results can be reproduced using the BRUIT-FM Python toolbox, available at https://gitlab.ifremer.fr/anr-bruitfm/bruit-fm-toolbox.
Abstract:
Relating a set of variables X to a response y is crucial in chemometrics. A quantitative prediction objective can be enriched by qualitative data interpretation, for instance by locating the most influential features. When high-dimensional problems arise, dimension reduction techniques can be used. Most notable are projections (e.g. Partial Least Squares or PLS ) or variable selections (e.g. lasso). Sparse partial least squares combine both strategies, by blending variable selection into PLS. The variant presented in this paper, Dual-sPLS, generalizes the classical PLS1 algorithm. It provides balance between accurate prediction and efficient interpretation. It is based on penalizations inspired by classical regression methods (lasso, group lasso, least squares, ridge) and uses the dual norm notion. The resulting sparsity is enforced by an intuitive shrinking ratio parameter. Dual-sPLS favorably compares to similar regression methods, on simulated and real chemical data.
Abstract: Denoising, detrending, deconvolution: usual restoration tasks, traditionally decoupled. Coupled formulations entail
complex ill-posed inverse problems. We propose PENDANTSS
for joint trend removal and blind deconvolution of sparse peak-like signals. It blends a parsimonious prior with the hypothesis
that smooth trend and noise can somewhat be separated by low-pass filtering. We combine the generalized pseudo-norm ratio
SOOT/SPOQ sparse penalties lp/lq with the BEADS ternary
assisted source separation algorithm. This results in a both
convergent and efficient tool, with a novel Trust-Region block
alternating variable metric forward-backward approach. It outperforms comparable methods, when applied to typically peaked
analytical chemistry signals. Reproducible code is provided.
Motivation: The cellular system of a living organism is composed of interacting bio-molecules that control cellular processes at multiple levels. Their correspondences are represented by tightly regulated molecular networks. The increase of omics technologies has favored the generation of large-scale disparate data and the consequent demand for simultaneously using molecular and functional interaction networks: gene co-expression, protein-protein interaction (PPI), genetic interaction, and metabolic networks. They are rich sources of information at different molecular levels, and their effective integration is essential to understand cell functioning and their building blocks (proteins). Therefore, it is necessary to obtain informative representations of proteins and their proximity, that are not fully captured by features extracted directly from a single informational level. We propose BraneMF, a novel random walk-based matrix factorization method for learning node representation in a multilayer network, with application to omics data integration.
Results:
We test BraneMF with PPI networks of Saccharomyces cerevisiae, a well-studied yeast model organism. We demonstrate the applicability of the learned features for essential multi-omics inference tasks: clustering, function and PPI prediction. We compare it to state-of-the-art integration methods for multilayer network. BraneMF outperforms baseline methods by achieving high prediction scores for a variety of downstream tasks. The robustness of results is assessed by an extensive parameter sensitivity analysis.
Availability: BraneMF is freely available at: https://github.com/Surabhivj/BraneMF
Background: Gene expression is regulated at different molecular levels, including
chromatin accessibility, transcription, RNA maturation, and transport. These
regulatory mechanisms have strong connections with cellular metabolism. In order
to study the cellular system and its functioning, omics data at each molecular
level can be generated and efficiently integrated. Here, we propose BRANEnet,
a novel multi-omics integration framework for multilayer heterogeneous networks.
BRANEnet is an expressive, scalable, and versatile method to learn node
embeddings, leveraging random walk information within a matrix factorization
framework. Our goal is to efficiently integrate multi-omics data to study different
regulatory aspects of multilayered processes that occur in organisms. We evaluate
our framework using multi-omics data of Saccharomyces cerevisiae, a well-studied
yeast model organism.
Results: We test BRANEnet on transcriptomics (RNA-seq) and targeted
metabolomics (NMR) data for wild-type yeast strain during a heat-shock time
course of 0, 20, and 120 minutes. Our framework learns features for differentially
expressed bio-molecules showing heat stress response. We demonstrate the
applicability of the learned features for targeted omics inference tasks:
transcription factor (TF)-target prediction, integrated omics network (ION)
inference, and module identification. The performance of BRANEnet is
compared with existing network integration methods. Our model outperforms
baseline methods by achieving high prediction scores for a variety of downstream
tasks
Abstract:
Transcription initiation is a tightly regulated process that is crucial for many aspects of prokaryotic physiology. High-throughput transcription start site (TSS) mapping can shed light on global and local regulation of transcription initiation, which in turn may help us understand and predict microbial behavior. In this study, we used Capp-Switch sequencing to determine the TSS positions in the genomes of three model solventogenic clostridia: Clostridium acetobutylicum ATCC 824, C. beijerinckii DSM 6423, and C. beijerinckii NCIMB 8052. We first refined the approach by implementing a normalization pipeline accounting for gene expression, yielding a total of 12,114 mapped TSSs across the species. We further compared the distributions of these sites in the three strains. Results indicated similar distribution patterns at the genome scale, but also some sharp differences, such as for the butyryl-CoA synthesis operon, particularly when comparing C. acetobutylicum to the C. beijerinckii strains. Lastly, we found that promoter structure is generally poorly conserved between C. acetobutylicum and C. beijerinckii. A few conserved promoters across species are discussed, showing interesting examples of how TSS determination and comparison can improve our understanding of gene expression regulation at the transcript level.
IMPORTANCE Solventogenic clostridia have been employed in industry for more than a century, initially being used in the acetone-butanol-ethanol (ABE) fermentation process for acetone and butanol production. Interest in these bacteria has recently increased in the context of green chemistry and sustainable development. However, our current understanding of their genomes and physiology limits their optimal use as industrial solvent production platforms. The gene regulatory mechanisms of solventogenesis are still only partly understood, impeding efforts to increase rates and yields. Genome-wide mapping of transcription start sites (TSSs) for three model solventogenic Clostridium strains is an important step toward understanding mechanisms of gene regulation in these industrially important bacteria.
Keywords: Industrial Microbiology; green chemistry; sustainable development; prokaryote; transcription start site (TSS); gene regulatory mechanisms; acetone-butanol-ethanol (ABE) fermentation
Abstract: We propose a method to reconstruct sparse signals degraded by a nonlinear
distortion and acquired at a limited sampling rate.
Our method formulates the reconstruction problem as a nonconvex minimization of
the sum of a data fitting term and a penalization term.
In contrast with most previous works which settle for approximated local
solutions, we seek for a global solution to the obtained challenging nonconvex
problem.
Our global approach relies on the so-called Lasserre relaxation of polynomial
optimization.
We here specifically include in our approach the case of piecewise rational
functions, which makes it possible to address a wide class of nonconvex exact and
continuous relaxations of the $\ell_{0}$ penalization function.
Additionally, we study the complexity of the optimization problem.
It is shown how to use the structure of the problem to lighten the computational
burden efficiently.
Finally, numerical simulations illustrate the benefits of our method in terms of
both global optimality and signal reconstruction.
Keywords: polynomial and rational optimization, global optimization, l0
penalization, sparse modelling
Abstract:
Background: The degradation of cellulose and hemicellulose molecules into
simpler sugars such as glucose is part of the second generation biofuel production
process. Hydrolysis of lignocellulosic substrates is usually performed by enzymes
produced and secreted by the fungus Trichoderma reesei. Studies identifying
transcription factors involved in the regulation of cellulase production have been
conducted but no overview of the whole regulation network is available. A
transcriptomic approach with mixtures of glucose and lactose, used as a substrate
for cellulase induction, was used to help us decipher missing parts in the network.
Results: Experimental results confirmed the impact of sugar mixture on the
enzymatic cocktail composition. The transcriptomic study shows a temporal
regulation of the main transcription factors and a lactose concentration impact
on the transcriptional profile. A gene regulatory network (GRN) built using the
BRANE Cut software reveals three sub-networks related to i) a positive
correlation between lactose concentration and cellulase production, ii) a
particular dependence of the lactose onto the beta-glucosidase regulation and iii) a
negative regulation of the development process and growth.
Conclusions: This work is the first investigating a transcriptomic study regarding
the effects of pure and mixed carbon sources in a fed-batch mode. Our study
expose a co-orchestration of xyr1, clr2 and ace3 for cellulase and hemicellulase
induction and production, a fine regulation of the beta-glucosidase and a decrease of
growth in favor of cellulase production. These conclusions provide us with
potential targets for further genetic engineering leading to better
cellulase-producing strains.
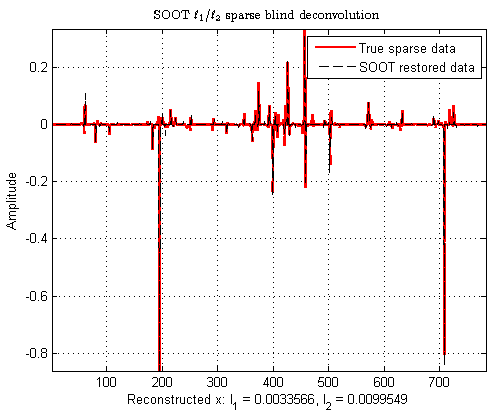
Abstract: Underdetermined or ill-posed inverse problems require additional information for sound solutions with tractable optimization algorithms. Sparsity yields consequent heuristics to that matter, with numerous applications in signal restoration, image recovery, or machine learning. Since the l0 count measure is barely tractable, many statistical or learning approaches have invested in computable proxies, such as the l1 norm. However, the latter does not exhibit the desirable property of scale invariance for sparse data. Extending the SOOT Euclidean/Taxicab l1-over-l2 norm-ratio initially introduced for blind deconvolution, we propose SPOQ, a family of smoothed (approximately) scale-invariant penalty functions. It consists of a Lipschitz-differentiable surrogate for lp-over-lq quasi-norm/norm ratios with p in ]0,2[ and q>=2. This surrogate is embedded into a novel majorize-minimize trust-region approach, generalizing the variable metric forward-backward algorithm. For naturally sparse mass-spectrometry signals, we show that SPOQ significantly outperforms l0, l1, Cauchy, Welsch, SCAD and Cel0 penalties on several performance measures. Guidelines on SPOQ hyperparameters tuning are also provided, suggesting simple data-driven choices.
With huge data acquisition progresses realized in the past decades and acquisition
systems now able to produce high resolution grids and point clouds, the digitization of
physical terrains becomes increasingly more precise. Such extreme quantities of
generated and modeled data greatly impact computational performances on many
levels of high-performance computing (HPC): storage media, memory requirements,
transfer capability, and finally simulation interactivity, necessary to exploit this instance
of big data. Efficient representations and storage are thus becoming "enabling
technologies'' in HPC experimental and simulation science (Foster et al.}, Computing Just What You Need: Online Data Analysis and Reduction at Extreme Scales, 2017). We propose HexaShrink,
an original decomposition scheme for structured hexahedral volume meshes. The
latter are used for instance in biomedical engineering, materials science, or
geosciences. HexaShrink provides a comprehensive framework allowing efficient mesh
visualization and storage. Its exactly reversible multiresolution decomposition yields a
hierarchy of meshes of increasing levels of details, in terms of either geometry,
continuous or categorical properties of cells.
Starting with an overview of volume meshes compression techniques, our contribution
blends coherently different multiresolution wavelet schemes in different dimensions. It
results in a global framework preserving discontinuities (faults) across scales,
implemented as a fully reversible upscaling at different resolutions. Experimental
results are provided on meshes of varying size and complexity. They emphasize the consistency of the proposed representation, in terms of visualization, attribute
downsampling and distribution at different resolutions. Finally, HexaShrink yields gains
in storage space when combined to lossless compression techniques.
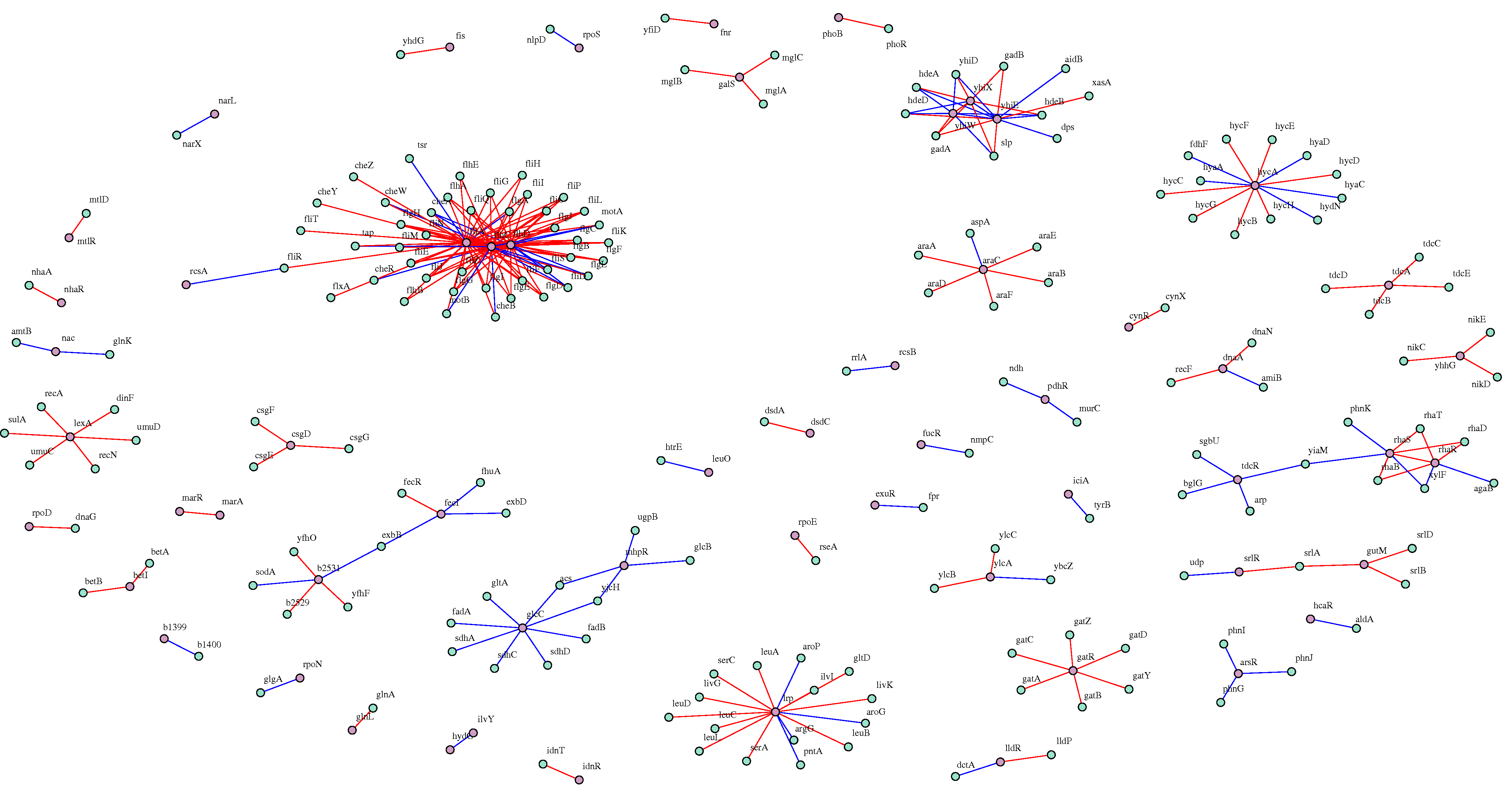
Discovering meaningful gene interactions is crucial for the identification of novel regulatory processes in cells. Building accurately the related graphs remains challenging due to the large number of possible solutions from available data. Nonetheless, enforcing a priori on the graph structure, such as modularity, may reduce network indeterminacy issues. BRANE Clust (Biologically-Related A priori Network Enhancement with Clustering) refines gene regulatory network (GRN) inference thanks to cluster information. It works as a post-processing tool for inference methods (i.e. CLR, GENIE3). In BRANE Clust, the clustering is based on the inversion of systems of linear equations involving a graph-Laplacian matrix promoting a modular structure. Our approach is validated on DREAM4 and DREAM5 datasets with objective measures, showing significant comparative improvements. We provide additional insights on the discovery of novel regulatory or co-expressed links in the inferred Escherichia coli network evaluated using the STRING database. The comparative pertinence of clustering is discussed computationally (SIMoNe, WGCNA, X-means) and biologically (RegulonDB). BRANE Clust software is available at: http://www-syscom.univ-mlv.fr/~pirayre/Codes-GRN-BRANE-clust.html.
The growing complexity of Cyber-Physical Systems (CPS), together with increasingly available parallelism provided by multi-core chips, fosters the parallelization of simulation. Simulation speed-ups are expected from co-simulation and parallelization based on model splitting into weak-coupled sub-models, as for instance in the framework of Functional Mockup Interface (FMI). However, slackened synchronization between sub-models and their associated solvers running in parallel introduces integration errors, which must be kept inside acceptable bounds. CHOPtrey denotes a forecasting framework enhancing the performance of complex system co-simulation, with a trivalent articulation. First, we consider the framework of a Computationally Hasty Online Prediction system (CHOPred). It allows to improve the trade-off between integration speed-ups, needing large communication steps, and simulation precision, needing frequent updates for model inputs. Second, smoothed adaptive forward prediction improves co-simulation accuracy. It is obtained by past-weighted extrapolation based on Causal Hopping Oblivious Polynomials (CHOPoly). And third, signal behavior is segmented to handle the discontinuities of the exchanged signals: the segmentation is performed in a Contextual and Hierarchical Ontology of Patterns (CHOPatt). Implementation strategies and simulation results demonstrate the framework ability to adaptively relax data communication constraints beyond synchronization points which sensibly accelerate simulation. The CHOPtrey framework extends the range of applications of standard Lagrange-type methods, often deemed unstable. The embedding of predictions in lag-dependent smoothing and discontinuity handling demonstrates its practical efficiency.
Comprehensive Two dimensional gas chromatography (GCxGC, or GC2D) plays a central role into the elucidation of complex samples. The automation of the identification of peak areas is of prime interest to obtain a fast and repeatable analysis of chromatograms. To determine the concentration of compounds or pseudo-compounds, templates of blobs are defined and superimposed on a reference chromatogram. The templates then need to be modified when different chromatograms are recorded. In this study, we present a chromatogram and template alignment method based on peak registration called BARCHAN. Peaks are identified using a robust mathematical morphology tool. The alignment is performed by a probabilistic estimation of a rigid transformation along the first dimension, and a non-rigid transformation in the second dimension, taking into account noise, outliers and missing peaks in a fully automated way. Resulting aligned chromatograms and masks are presented on two datasets. The proposed algorithm proves to be fast and reliable. It significantly reduces the time to results for GCxGC analysis.
Background
Inferring gene networks from high-throughput data (RNA-Seq) constitutes
an important step in the discovery of relevant regulatory relationships in organism cells.
Despite the large number of available Gene Regulatory Network inference methods, the problem remains challenging: the underdetermination in the space of possible solutions requires additional constraints that incorporate a priori information on gene interactions.
Results
Weighting all possible pairwise gene relationships
by a probability of edge presence, we formulate the regulatory network inference
as a discrete variational problem on graphs. We enforce biologically plausible
coupling between groups and types of genes by minimizing an edge labeling
functional coding for a priori structures.
The optimization is carried out with Graph cuts, an
approach popular in image processing and computer vision. We compare the
inferred regulatory networks to results achieved by the mutual-information-based
Context Likelihood of Relatedness (CLR) method and to the state-of-the-art
GENIE3, winner of the DREAM4 multifactorial challenge.
Conclusions
Our BRANE Cut approach infers more accurately the five DREAM4 in silico networks (with improvements from 6% to 11%). On a real Escherichia coli compendium, an improvement of 11.8% compared to CLR and 3% compared to GENIE3 is obtained in terms of Area Under Precision-Recall curve. Up to 48 additional verified interactions are obtained over GENIE3 for a given precision. On this dataset involving 4345 genes, our method achieves a performance similar to that of GENIE3, while being more than seven times faster.
The BRANE Cut code is available at: http://www-syscom.univ-mlv.fr/~pirayre/Codes-GRN-BRANE-cut.html
Keywords: Gene network inference, high throughput data, optimization, network theory, maximum flow
AbstractThe l1/l2 ratio regularization function has shown good performance for retrieving sparse signals in a number of recent works, in the context of blind deconvolution. Indeed, it benefits from a scale invariance property much desirable in the blind context. However, the l1/l2 function raises some difficulties when solving the nonconvex and nonsmooth minimization problems resulting from the use of such a penalty term in current restoration methods. In this paper, we propose a new penalty based on a smooth approximation to the l1/l2 function. In addition, we develop a proximal-based algorithm to solve variational problems involving this function and we derive theoretical convergence results. We demonstrate the effectiveness of our method through a comparison with a recent alternating optimization strategy dealing with the exact l1/l2 term, on an application to seismic data blind deconvolution (Ricker wavelet).
This paper jointly addresses the problems of chromatogram baseline correction and noise reduction.
The proposed approach is based on modeling the series of chromatogram peaks as sparse
with sparse derivatives,
and on modeling the baseline as a low-pass signal.
A convex optimization problem is formulated so as to encapsulate these non-parametric models.
To account for the positivity of chromatogram peaks, an asymmetric penalty functions is utilized.
A robust, computationally efficient, iterative algorithm is developed that
is guaranteed to converge to the unique optimal solution.
The approach, termed Baseline Estimation And Denoising with Sparsity (BEADS), is evaluated and compared with two state-of-the-art methods using both simulated and real chromatogram data.
Unveiling meaningful geophysical information from seismic data requires to deal with both random and structured "noises". As their amplitude may be greater than signals of interest (primaries), additional prior information is especially important in performing efficient signal separation. We address here the problem of multiple reflections, caused by wave-field bouncing between layers. Since only approximate models of these phenomena are available, we propose a flexible framework for time-varying adaptive filtering of seismic signals, using sparse representations, based on inaccurate templates. We recast the joint estimation of adaptive filters and primaries in a new convex variational formulation. This approach allows us to incorporate plausible knowledge about noise statistics, data sparsity and slow filter variation in parsimony-promoting wavelet frames. The designed primal-dual algorithm solves a constrained minimization problem that alleviates standard regularization issues in finding hyperparameters. The approach demonstrates significantly good performance in low signal-to-noise ratio conditions, both for simulated and real field seismic data.
Keywords: Convex optimization; Parallel algorithms; Wavelet transforms; Adaptive filters; Geophysical signal
processing; Signal restoration; Sparsity; Signal separation.
Valve trays column design for gas treatment still relies on empirical correlations developed on pilot units. The available correlations lead to large discrepancies and thus more experimental works are needed. The present hydrodynamic study was carried out on a Plexiglas 1.26 m per 0.1905 m absorption column containing four V-4 Glitsch valve trays. Water/air system was used at atmospheric pressure and ambient temperature. Liquid rate per weir unit length was varied between 3.2x10-3 m3.(m.s)-1 and 24.3x10-3 m3.(m.s)-1 and the kinetic gas factor between 0 and 3.5 Pa0.5.
The following hydrodynamic parameters were determined: tray pressure drop, valves pressure drop, clear liquid height, mean emulsion height and liquid mean hold up on the tray. Correlations for clear liquid height, liquid mean hold up and emulsion height are proposed.
Emulsion profiles characterisation was possible due to video records post-processing. Four different behaviours are identified for emulsion profiles according to liquid and gas velocities.
Significant behaviour changes on the hydrodynamic parameters allowed the identification of three system limits: dumping, weeping and pre-flooding. Correlations are proposed for these limits and an operational diagram is presented.
Adaptive subtraction is a key element in predictive multiple-suppression methods. It
minimizes misalignments and amplitude differences between modeled and actual multiples, and thus reduces multiple contamination in the dataset after subtraction. The challenge consists in attenuating multiples without distorting primaries, despite
the high cross-correlation between their waveform.
For this purpose,
this complicated wide-band problem is decomposed into a set of more tractable narrow-band problems using a 1D complex wavelet frame. This decomposition enables a single-pass adaptive subtraction
via single-sample (unary) complex Wiener filters, consistently estimated on overlapping windows in a complex wavelet transformed domain. Each unary filter compensates amplitude differences within its frequency support, and rectifies more robustly small and large misalignment errors through phase and integer delay corrections . This approach greatly simplifies the matching filter estimation and, despite its simplicity, compares promisingly with standard adaptive 2D methods, on both synthetic and field data.
Keywords: multiples, processing, filtering, cross-correlation, wavelet, adaptive, model
The richness of natural images makes the quest for optimal representations in image processing and computer vision challenging. The latter observation has not prevented the design of image representations, which trade off between efficiency and complexity, while achieving accurate rendering of smooth regions as well as reproducing faithful contours and textures. The most recent ones, proposed in the past decade, share an hybrid heritage highlighting the multiscale and oriented nature of edges and patterns in images. This paper presents a panorama of the aforementioned literature on decompositions in multiscale, multi-orientation bases or dictionaries. They typically exhibit redundancy to improve sparsity in the transformed domain and sometimes its invariance with respect to simple geometric deformations (translation, rotation). Oriented multiscale dictionaries extend traditional wavelet processing and may offer rotation invariance. Highly redundant dictionaries require specific algorithms to simplify the search for an efficient (sparse) representation. We also discuss the extension of multiscale geometric decompositions to non-Euclidean domains such as the sphere or arbitrary meshed surfaces. The etymology of panorama suggests an overview, based on a choice of partially overlapping "pictures". We hope that this paper will contribute to the appreciation and apprehension of a stream of current research directions in image understanding.
Highly boosted spark ignition engines must confront violent forms of pre-ignition limiting the maximal low-end
torque. French research institute IFP presents here an innovative tool allowing a better understanding of this phe-
nomenon and a structured reasoning considering all potential causes of this phenomenon. Advanced statistical
analyses of the combustion process and direct visualisations inside the combustion chamber are successfully
combined to accurately assess the development of pre-ignition. This coupled approach provides an efficient tool
for analysis and development of new engines and new control concepts on IFP test beds.
An important issue with oversampled FIR analysis filter banks (FBs) is to determine inverse synthesis FBs, when they exist. Given any complex oversampled FIR analysis FB, we first provide an algorithm to determine whether there exists an inverse FIR synthesis system. We also provide a method to ensure the Hermitian symmetry property on the synthesis side, which is serviceable to processing real-valued signals. As an invertible analysis scheme corresponds to a redundant decomposition, there is no unique inverse FB. Given a particular solution, we parameterize the whole family of inverses through a null space projection. The resulting reduced parameter set simplifies design procedures, since the perfect reconstruction constrained optimization problem is recast as an unconstrained optimization problem. The design of optimized synthesis FBs based on time or frequency localization criteria is then investigated, using a simple yet efficient gradient algorithm.
The use of multicomponent images has become widespread with the improvement of multisensor systems having increased spatial and spectral resolutions. However, the observed images are often corrupted by an additive Gaussian noise. In this paper, we are interested in multichannel image denoising based on a multiscale representation of the images. A multivariate statistical approach is adopted to take into account both the spatial and the inter-component correlations existing between the different wavelet subbands. More precisely, we propose a new parametric nonlinear estimator which generalizes many reported denoising methods. The derivation of the optimal parameters is achieved by applying Stein's principle in the multivariate case. Experiments performed on multispectral remote sensing images clearly indicate that our method outperforms conventional wavelet denoising techniques
Dual-tree wavelet decompositions have recently gained much popularity, mainly due to their ability to provide an accurate directional analysis of images combined with a reduced redundancy. When the decomposition of a random process is performed -- which occurs in particular when an additive noise is corrupting the signal to be analyzed -- it is useful to characterize the statistical properties of the dual-tree wavelet coefficients of this process. As dual-tree decompositions constitute overcomplete frame expansions, correlation structures are introduced among the coefficients, even when a white noise is analyzed. In this paper, we show that it is possible to provide an accurate description of the covariance properties of the dual-tree coefficients of a wide-sense stationary process. The expressions of the (cross-)covariance sequences of the coefficients are derived in the one and two-dimensional cases. Asymptotic results are also provided, allowing to predict the behaviour of the second-order moments for large lag values or at coarse resolution. In addition, the cross-correlations between the primal and dual wavelets, which play a primary role in our theoretical analysis, are calculated for a number of classical wavelet families. Simulation results are finally provided to validate these results.
Comprehensive two-dimensional gas chromatography (GCxGC or GC2D) is a major
advance for the detailed characterisation of petroleum products. This technique is based on two
orthogonal dimensions of separation achieved by two chromatographic capillary columns of different
chemistries and selectivities. High-frequency sampling between the two columns is achieved by a
modulator, ensuring that the whole sample is transferred and analysed continuously in both separations.
Thus, the peak capacity and the resoluting power dramatically increase. Besides, highly structured 2D
chromatograms are obtained upon the volatility and the polarity of the solute to provide more accurate
molecular identification of hydrocarbons. In this paper fundamental and practical considerations for
implementation of GCxGC are reviewed. Selected applications obtained using a prototype of a GCxGC
chromatograph developed in-house highlight the potential of the technique for molecular
characterisation of middle distillates, sulphur speciation in diesel and analysis of effluents from petrochemical processes
We propose a two-dimensional generalization to the M-band case of the dual-tree decomposition structure (initially
proposed by Kingsbury and further investigated by Selesnick) based on a Hilbert pair of wavelets. We particularly address:
1) the construction of the dual basis and 2) the resulting directional analysis. We also revisit the necessary pre-processing stage in the M-band case. While several reconstructions are possible because of the redundancy of the representation, we propose a new optimal signal reconstruction technique, which minimizes potential estimation errors. The effectiveness of the proposed M-band decomposition is demonstrated via denoising comparisons on several image types (natural, texture, seismics), with various M-band wavelets and thresholding strategies. Significant improvements in terms of both overall noise reduction and direction preservation
are observed.
Keywords: Direction selection; Hilbert transform; dual-tree; image denoising; wavelets
The detailed characterisation of middle distillates is essential for a better understanding of reactions involved in refining process. Owing
to higher resolution power and enhanced sensitivity, comprehensive two-dimensional gas chromatography (GCxGC) is a powerful tool
for improving characterisation of petroleum samples. The aim of this paper is to compare GCxGC and various ASTM methods - gas
chromatography (GC), liquid chromatography (LC) and mass spectrometry (MS) - for group type separation and detailed hydrocarbon
analysis. Best features of GCxGC are demonstrated and compared to these techniques in terms of cost, time consumption and accuracy. In particular, a new approach of simulated distillation (SimDis-GCxGC) is proposed: compared to the standard method ASTM D2887 it gives
unequal information for better understanding of conversion process.
Keywords: Comprehensive two-dimensional gas chromatography;
ASTM methods;
Simulated distillation;
Group type separation;
Hydrocarbons
Seismic exploration provides information about the ground substructures. Seismic images are generally corrupted by several noise sources. Hence, efficient denoising procedures are required to improve the detection of essential geological information. Wavelet bases provide sparse representation for a wide class of signals and images. This property makes them good candidates for efficient filtering tools, allowing the separation of signal and noise coefficients. Recent works have improved their performance by modelling the intra- and inter-scale coefficient dependencies using hidden Markov models, since image features tend to cluster and persist in the wavelet domain. This work focuses on the use of lapped transforms associated with hidden Markov modelling. Lapped transforms are traditionally viewed as block-transforms, composed of M pass-band filters. Seismic data present oscillatory patterns and lapped transforms oscillatory bases have demonstrated good performances for seismic data compression. A dyadic like representation of lapped transform coefficient is possible, allowing a wavelet-like modelling of coefficients dependencies. We show that the proposed filtering algorithm often outperforms the wavelet performance both objectively (in terms of SNR) and subjectively: lapped transform better preserve the oscillatory features present in seismic data at low to moderate noise levels.
Keywords: seismic data filtering; lapped transforms; hidden Markov models
Comprehensive two-dimensional gas chromatography (GCxGC) has been investigated for the characterization of high valuable petrochemical samples from dehydrogenation of n-paraffins, Fischer-Tropsch and oligomerization processes. GCxGC separations, performed
using a dual-jets CO2 modulator, were optimized using a test mixture representative of the hydrocarbons found in petrochemicals. For complex
samples, a comparison of GCxGC qualitative and quantitative results with conventional gas chromatography (1D-GC) has demonstrated an
improved resolution power of major importance for the processes: the group type separation has permitted the detection of aromatic compounds
in the products from dehydrogenation of n-paraffins and from oligomerization, and the separation of alcohols from other hydrocarbons in
Fischer-Tropsch products.
Keywords: Gas chromatography, comprehensive two-dimensional;
Petrochemical samples;
Hydrocarbons
Data processing applied to GCxGC. Applications to the petroleum industry - Traitement de données d'échantillons complexes en GCxGC (quantification, comparaison d'échantillons, post-traitement). Applications à l'industrie pétrolière et agro-alimentaire, Benoit Celse, F. Bertoncini, M. Moreaud, L. Duval, M. Courtiade, C. Dartiguelongue, S. Esnault, D. Cavagnino, in Gas chromatography and 2D-gas chromatography for petroleum industry: The race for selectivity, (Editors: Bertoncini Fabrice; Courtiade-Tholance Marion; Thiébaut Didier), 2013 [book+blog]
Wavelet transform for the denoising of multivariate images,
Caroline Chaux, Amel Benazza-Benyahia, Jean-Christophe Pesquet, Laurent Duval, in Multivariate Image Processing, Jocelyn Chanussot, Christophe Collet, Kacem Chehdi, editors, ISTE Ltd and John Wiley and Sons Inc, January 2010
[book+hal]
An increasing attention is being paid to multispectral images for a great number
of applications (medicine, agriculture, archeology, forestry, coastal management, remote sensing) because many features of the underlying scene have unique spectral
characteristics that become apparent in imagery when viewing combinations of its
different components. [...]
Despite the dramatical technological advances in terms of spatial and spectral resolutions of the radiometers, data still suffer from several degradations. For instance, the
sensor limited aperture, aberrations inherent to optical systems and mechanical vibrations create a blur effect in remote sensing images [JAI 89]. In optical remote sensing
imagery, there are also many noise sources. Firstly, the number of photons received
by each sensor during the obturation time may fluctuate around its average implying
a photon noise. A thermal noise may be caused by the electronics of the recording
and the communication channels during the data downlinking. Intermittent saturations of any detector in a radiometer may give rise to an impulsive noise whereas a
structured periodic noise is generally caused by interferences between electronic components. Detector striping (resp. banding) are consequences of calibration differences
among individual scanning detectors (resp. from scan-to-scan). Besides, component-to-component misregistration may occur : corresponding pixels in different components are not systematically associated with the same position on the ground.
As a result, it is mandatory to apply deblurring, denoising and geometric corrections
to the degraded observations in order to fully exploit the information they contain. In
this respect, it is used to distinguish between on-board and on-ground processing. Indeed, on-board procedures should simultaneously fulfill real-time constraints and low
mass memory requirements. The involved acquisition bit-rates are high (especially for
very high resolution missions) and hence, they complicate the software implementation of enhancement processing. [...]
Communications à congrès/Conference papers
Refinable-precision in mesh compression for upscaling and upgridding in
reservoir simulation with HexaShrink, Lauriane Bouard, Laurent Duval, Christophe Preux, Frédéric Payan, Marc Antonini, RING Meeting, September 2019, Nancy, France [site]
Efficiency is also the main concern of Laurianne Bouard (PhD student, IFPEN and Univ. C�te d�Azur) et al., who propose a multi-resolution scheme to compress corner-point hexahedral grids for flow applications.
Manipulation of large data volumes is becoming a concern in the field of simulation. In reservoir simulation, grids are complex structures composed of heterogeneous objects, with a potentially large number of cells. HexaShrink is a perfectly reversible multiscale decomposition tool based on 3D wavelet transformation, dedicated to structured hexahedral meshes. It provides a representation of mesh geometry and properties at different resolutions, coherently preserving discontinuities such as fault networks. This lossless compression method was initially designed for storage and transfer. Here we evaluate its suitability in the context of two-phase flow simulations. Initial results demonstrate comparable impacts of low-resolution grids on injected water. This suggests that embedding low resolution meshes can serve accelerated appromixate simulation results with little overhead, in a consistent upscaling and upgriding fashion.
We revisit a validated PLS model for property prediction on
NMR spectra. We investigate the benefits (precision, robustness,
sensitivity) of integrating advanced optimization
algorithms to usual least-squares in baseline/smoothing/
prediction.
Des méthodes de simulation employant des maillages sont mises en œuvre dans de nombreux champs scientifiques pour caractériser des phénomènes physiques sous-jacents. Les besoins croissants en précision induisent l'utilisation de maillages toujours plus volumineux, et entrainent des problèmes de visualisation, de manipulation ou de stockage des données. En géosciences, d'immenses zones géologiques sont modélisées par des maillages hexaédriques géométriquement complexes, émulant des propriétés physiques du sous-sol. En combinant différents types d'ondelettes classiques ou morphologiques qui préservent les discontinuités, HexaShrink (HS) apporte à cette problématique une solution multi-échelle cohérente. Dans cet article, nous analysons les performances de compression de HS, par l'étude exhaustive de sept maillages hétérogènes. Globalement, les taux de compression accrus, obtenus grâce à la décomposition, sont satisfaisants. Néanmoins, l'analyse distincte des différentes composantes définissant les maillages (géométrie, propriétés) révèle que l'utilisation d'encodeurs génériques n'est pas toujours optimale, ouvrant des perspectives vers des encodeurs multi-échelles plus à même d'exploiter les structures intrinsèques des niveaux de détail.
Arthur Marmin, Marc Castella, Jean-Christophe Pesquet, Laurent Duval, Signal Reconstruction from Sub-sampled and Nonlinearly Distorted Observations,
EUSIPCO 2018, Rome, Italy, September 3-7, 2018
As field seismic data sizes are dramatically increasing toward exabytes, automating the labeling of "structural monads" - corresponding to geological patterns and yielding subsurface interpretation - in a huge amount of available information would drastically reduce interpretation time. Since customary designed features may
not account for the gradual deformation observable in seismic data, we propose to adapt the wavelet-based scattering network methodology with a tessellation of geophysical images. Its invariances are expected to be able to thwart the effect of the tectonics. The sparse structure of extracted feature vectors suggest to resort to dimension reduction methods before classification. The most promising one is based on a tessellated version of scattering decompositions, combined with a standard affine PCA classifier. Extensive comparative results on a four-class seismic database show the effectiveness of the proposed method in terms of seismic data labeling and object retrieval, in affordable computational time.
Décomposition progressive de maillages hexaédriques avec
discontinuités : application aux modèles géologiques, GRETSI 2017
HOGMep: variational Bayes and higher-order graphical models applied to Joint Image Recovery and Segmentation, ICIP 2017, Sep. 17-20, 2017, Beijing, China [page]+hal]
Variational Bayesian approaches have been successfully applied to image segmentation. They usually rely on a Potts model for the hidden label variables and a Gaussian assumption on pixel intensities within a given class. Such models may however be limited, especially in the case of multicomponent images. We overcome this limitation with HOGMep, a Bayesian formulation based on a higher-order graphical model (HOGM) on labels and a Multivariate Exponential Power (MEP) prior for intensities in a class. Then, we develop an efficient statistical estimation method to solve the associated problem. Its flexibility accommodates to a broad range of applications, demonstrated on multicomponent image segmentation and restoration.
Building high-fidelity system-level models of Cyber-Physical Systems (CPS) is a challenging duty.
A first problem is the diversity of modeling and simulation environments used by the various involved multi-disciplinary teams. Particular environments are preferred for a specific use, due to distinctive strengths (modeling language, libraries, solvers, cost, etc.). The Functional Mock-up Interface (FMI) specification has been proposed to improve this issue.
A second problem is the growing complexity of such high-fidelity models and their induced prohibitive CPU execution time. Indeed, major system-level simulation softwares are relying on sequential ODE/DAE solvers. They are currently unable to efficiently exploit the available parallelism provided by multi-core chips. In addition, CPS are commonly modeled as hybrid models where the major challenge resides in their numerous discontinuities. Indeed, discontinuities usually prevent high integration speeds with variable-step solvers.
We propose a modular co-simulation of a split model, where each sub-model is integrated with its own solver. Thanks to splitting, high integration speeds can be reached when using LSODAR (Livermore Solver for Ordinary Differential equations, with Automatic method switching for stiff and nonstiff problems, and with Root-finding),a variable step solver with a root-finding capability.% Indeed, interruption coming from unrelated events is avoided thanks to event's containment. Moreover events detection and location inside a sub-model can be processed faster because they involve a smaller set of variables.
Nevertheless, partitioning a complex model into several lesser complex sub-models also brings
some difficulties that need to be managed.
First, partitioning may add virtual algebraic loops, therefore involving delayed outputs, even with an efficient execution order.
To avoid the latter, we propose in~\cite{Benkhaled_A_Simpra} a new co-simulation method based on a refined scheduling approach. This technique, denoted ``RCosim'', retains the speed-up advantage of modular co-simulation thanks to the parallel execution of the sub-models. Furthermore, it improves the accuracy of simulation results through an offline scheduling of operations that takes care of model input/output dynamics.
Second, partitioning and even co-simulation require synchronization between coupled models to exchange updated data to reduce numerical error propagation in simulation results.
Thus, tight synchronization, using small communication steps, is required between blocks. This greatly limits the possibilities to accelerate the simulation. % and eventually reach the real-time.
Adaptive communication steps may better handle changes in model dynamics.
Meanwhile, stability of multi-rate simulators
needs to be carefully assessed.
Data extrapolation over steps is expected to enhance the precision over large communication steps. However, complex models usually present non-linearities and discontinuities, entangling forecasts from past observations only.
We propose a Computationally Hasty Online Prediction framework (CHOPred) to stretch out synchronization steps with negligible precision changes in the simulation, at low-complexity.
It allows to improve the trade-off between speed-ups, needing large communication steps, and precision, needing frequent updates for model inputs.
It is based on a Contextual & Hierarchical Ontology of
Patterns (CHOPatt) that handles the discontinuities of exchanged signals by selecting appropriate
Causal Hopping Oblivious Polynomials (CHOPoly).
CHOPtrey
uses a time-depending oblivion faculty for polynomial extrapolation with an independent power weighting on past samples. It accounts for memory depth changes required to adapt to sudden variations. Computations are performed on frames of samples hopping at synchronization steps.%, allowing a low-complexity matrix formulation.
It is implemented on xMOD tool in combination with model splitting and parallel simulation. It is applied on a hybrid dynamical engine model where the split parts are exported as FMUs from Dymola.
Test results show effective simulation speed-up with imperceptible computational overheads. In addition, sustained or even improved simulation precision is obtained without noticeable instability.
Efficient GCxGC data treatment with BARCHAN algorithm (Blob Alignment for Robust Chromatographic Analysis) and anchor points (13th GCxGC SYMPOSIUM 2016)
Reconstruction de signaux parcimonieux à l'aide d'un algorithme rapide d'échantillonnage stochastique, septembre 2015, GRETSI, colloque international francophone de Traitement du Signal et de l'Image, Lyon, France
Deconvolution of seismic data with a regularized norm ratio, Audrey Repetti, Mai Quyen-Pham, Laurent Duval, Émilie Chouzenoux, Jean-Christophe Pesquet, ICIAM 2015, Eighth International Congress on Industrial and Applied Mathematics, "Sparsity-promoting seismic data analysis" minisymposium (program), with sparse deconvolution Matlab toolbox http://lc.cx/soot
[abstract|slides]
This introductory paper aims at summarizing some problems and state-of-the-art techniques encountered in image processing for material analysis and design. Developing generic methods for this purpose is a complex task given the variability of the different image acquisition modalities (optical, scanning or transmission electron microscopy; surface analysis instrumentation, electron tomography, micro-tomography...), and material composition (porous, fibrous, granular, hard materials, membranes, surfaces and interfaces...). This paper presents an overview of techniques that have been and are currently developed to address this diversity of problems, such as segmentation, texture analysis, multiscale and directional features extraction, stochastic models and rendering, among others. Finally, it provides references to enter the issues, challenges and opportunities in materials characterization.
Both random and structured perturbations affect seismic data. Their removal, to unveil meaningful geophysical information, requires additional priors. Seismic multiples are one form of structured perturbations related to wave-field bouncing. In this paper, we model these undesired signals through a time-varying filtering process accounting for inaccuracies in amplitude, time-shift and average frequency of available templates. We recast the problem of jointly estimating the filters and the signal of interest (primary) in a new convex variational formulation, allowing the incorporation of knowledge about the noise statistics. By making some physically plausible assumptions about the slow time variations of the filters, and by adopting a potential promoting the sparsity of the primary in a wavelet frame, we design a primal-dual algorithm which yields good performance in the provided simulation examples.
This tutorial paper aims at summarizing some problems, ranging from analytical chemistry to novel chemical sensors, that can be addressed with classical or advanced methods of signal and image processing. We gather them under the denomination of "chemical sensing". It is meant to introduce the special session "Signal Processing for Chemical Sensing" with a large overview of issues which have been and remain to be addressed in this application domain, including chemical analysis leading to PARAFAC/tensor methods, hyper spectral imaging, ion-sensitive sensors, artificial nose, chromatography, mass spectrometry, etc. For enlarging and illustrating the points of view of this tutorial, the invited papers of the session consider other applications (NMR, Raman spectroscopy, recognition of explosive compounds, etc.) addressed by various methods, e.g. source separation, Bayesian, and exploiting typical chemical signal priors like positivity, linearity, unit-concentration or sparsity.
Multiple attenuation is one of the greatest challenges in
seismic processing. Due to the high cross-correlation
between primaries and multiples, attenuating the latter
without distorting the former is a complicated problem.
We propose here a joint multiple model-based adaptive
subtraction, using single-sample unary filters' estimation
in a complex wavelet transformed domain. The method
offers more robustness to incoherent noise through redundant decomposition. It is first tested on synthetic
data, then applied on real-field data, with a single-model
adaptation and a combination of several multiple models.
Due to complex subsurface structure properties, seismic
records often suffer from coherent noises such as multiples.
These undesired signals may hide the signal of interest,
thus raising difficulties in interpretation. We propose
a new variational framework based on Maximum A Posteriori
(MAP) estimation. More precisely, the problem of
multiple removal is formulated as a minimization problem
involving time-varying filters, assuming that a disturbance
signal template is available and the target signal is sparse in
some orthonormal basis. We show that estimating multiples
is equivalent to identifying filters and we propose to employ
recently proposed convex optimization procedures based on
proximity operators to solve the problem. The performance
of the proposed approach as well as its robustness to noise is
demonstrated on realistically simulated data. [Keywords: convex optimization, wavelets, time-varying
filters, regularization]
Directional filters are commonly used tools in modern seismic
data processing to address coherent signals, depending
on their apparent slowness or slope. This operation enhances
the characterization of the great variety of signals present in
a seismic dataset that enables a better characterization of the
subsurface structure. This paper compares two complementary
local adaptive multiscale directional filters: a directional
filter bank based on dual-tree M-band wavelets and a novel
local slant stack transform (LSST) based filter in the timescale
domain. Their differences reside in redundancy levels
and slope (directional) resolution. A structural similarity index
measure has been employed to objectively compare both
approaches on a real seismic dataset example.
Multiple attenuation is a crucial task in seismic data processing because multiples usually cover primaries from fundamental reflectors. Predictive multiple suppression methods remove these multiples by building an adapted model, aiming at being subtracted from the original signal. However, before the subtraction is applied, a matching filter is required to minimize amplitude differences and misalignments between multiples and their prediction, and thus to minimize the multiples in the input dataset after the subtraction. In this paper we focus on the subtraction element. The proposed complex wavelet transform based approach simplifies the matching filter estimation.
Redundancy in wavelets and filter banks has the potential
to greatly improve signal and image denoising. Having de-
veloped a framework for optimized oversampled complex
lapped transforms, we propose their association with the sta-
tistically efficient Stein�s principle in the context of mean
square error estimation. Under Gaussian noise assumptions,
expectations involving the (unknown) original data are ex-
pressed using the observation only. Two forms of Stein�s Un-
biased Risk Estimators, derived in the coefficient and the spa-
tial domain respectively, are proposed, the latter being more
computationally expensive. These estimators are then em-
ployed for denoising with linear combinations of elementary
threshold functions. Their performances are compared to the
oracle, and addressed with respect to the redundancy. They
are finally tested against other denoising algorithms. They
prove competitive, yielding especially good results for tex-
ture preservation.
Seismic data and their complexity still challenge signal processing algorithms in several applications. The advent
of wavelet transforms has allowed improvements in tackling denoising problems. We propose here coherent noise
filtering in seismic data with the dual-tree M-band wavelet transform. They offer the possibility to decompose
data locally with improved multiscale directions and frequency bands. Denoising is performed in a deterministic
fashion in the directional subbands, depending of the coherent noise properties. Preliminary results show that
they consistently better preserve seismic signal of interest embedded in highly energetic directional noises than
discrete critically sampled and redundant separable wavelet transforms.
The Short Term Fourier Transform (STFT) is a classical linear time-frequency (T-F) representation. Despites
its relative simplicity, it has become a standard tool for the analysis of non-stationary signals. Since it provides a
redundant representation, it raises some issues such as (i) \optimal" window choice for analysis, (ii) existence and
determination of an inverse transformation, (iii) performance of analysis-modification-synthesis, or reconstruction
of selected components of the time-frequency plane and (iv) redundancy controllability for low-cost applications,
e.g. real-time computations. We address some of these issues, as well as the less often mentioned problem of
transform symmetry in the inverse, through oversampled FBs and their optimized inverse(s) in a slightly more
general setting than the discrete windowed Fourier transform.
The complexity of seismic data still challenges signal processing algorithms in several applications. The rediscovery
of wavelet transforms by J. Morlet et al. has allowed improvements in addressing several data representation
(local analysis, compression) and restoration problems. However, despites their achievements,
traditional approaches based on discrete and separable (both for computational purposes) wavelets fail at
efficiently representing directional or higher dimensional data features, such as line or plane singularities,
especially in severe noise conditions. Subsequent extensions to wavelets (multiscale pyramids, curvelets, contourlets, bandlets) have recently generated tremendous theoretical and practical interests.
They feature local and multiscale properties associated with a certain amount of redundancy, which
may represent an issue for huge datasets processing.
We propose here seismic data processing based on dual-tree M-band wavelet transforms. They
combine:
orthogonal M-band filter banks which better separate frequency bands in seismic data than wavelets,
due to the increased degrees of freedom in the filter design,
Hilbert transform and complex representation of seismic signals which have been effective, especially
for attributes definition,
with a relatively low redundancy (a factor of two). These transforms have been successfully applied to
random noise removal in traditional and remote sensing imagery.
We apply them to seismic data and address their potential for local slope analysis and coherent noise
(ground-roll) filtering.
Seismic data are subject to different kinds of unwanted perturbations. These random or organised noises,
which can be acquisition or processing related for instance, may disturb geophysical interpretations and
thwart attempts at automated processing methods. Since the relative features (e.g. amplitude, spectrum) of
the signals of interest and the noises may vary locally, signal and noise separation is obtained by a local
data-driven filtering with two or three-dimensional oversampled complex filter banks.
Filter banks in general decompose the noisy data onto frequency bands and directions on restricted subregions
(sub-images or sub-volumes), acting like a local FK with improved properties. The transforms
studied in this work present sub-regions smooth overlapping, to avoid tiling effects while allowing signal
reconstruction from the transformed domain. The proposed methodology uses limited redundancy filtering
that both yield enhanced noise robustness (due to oversampling) and tractable 2D or 3D processing, since
they are optimized to limit the redundancy cost.
Coupling those redundant transforms with a processing method designed to detect and compute locally
dominant directions, and to remove unwanted directions and random noise, leads to good visual results.
Tests were performed on 2D and 3D seismic data
Polychrom: a software for semi-automated quantitative gcxgc analysis with identification profiles,
Benoît Celse, Fabrice Bertoncini, Frédérik Adam, Nicolas Brodusch,
S´bastien Esnault, Laurent Duval,
Dalian International Symposia and Exhibition on Chromatography (DISEC 2007), 4th GCxGC Symposium, Dalian, China, June 2007 (DISEC 2007)
Automatic template fit in comprehensive two dimensional gas chromatography
Benoît Celse, Fabrice Bertoncini, Laurent Duval, Frédérik Adam
Dalian International Symposia and Exhibition on Chromatography (DISEC 2007), 4th GCxGC Symposium, Dalian, China, June 2007 (DISEC 2007)
Comprehensive two dimensional gas chromatography image segmentation using the level-set technique
Laurent Duval, Yacine Bourkeb, Benoît Celse, Fabrice Bertoncini, Frédérik Adam, Rachid Deriche
Dalian International Symposia and Exhibition on Chromatography (DISEC 2007), 4th GCxGC Symposium, Dalian, China, June 2007 (DISEC 2007)
Dual-tree wavelet transforms have recently gained popularity since they provide low-redundancy directional analyses
of images. In our recent work, dyadic real dual-tree decompositions have been extended to the M-band case, so adding much flexibility to this analysis tool. In this work, we propose to further extend this framework on two fronts by considering (i) biorthogonal and (ii) complex M-band dualtree decompositions. Denoising results are finally provided to demonstrate the validity of the proposed design rules.
Keywords: Wavelet transforms, Hilbert transforms, Image analysis, Image processing, Gaussian noise.
This paper addresses the implementation and comparison of
algorithms for real-time knock detection. Knock is an unwanted
abnormal combustion process that may damage engines
and limit their efficiency. For series vehicles, knock detection
is generally obtained from knock sensors that capture
other noise sources, thus requiring robust algorithms. In order
to estimate the performance of time-frequency and Kalman
filter based algorithms, a knock signal model is proposed and
the algorithms are tested under various noise conditions. Experiments
on modelled and real signals show the superiority
of the recently developed S-method with respect to extended
Kalman filtering.
Keywords: Knock, Real time systems, Time-Frequency Analysis, Kalman filtering, Wigner distributions
When an oversampled FIR filter bank structure is used for
signal analysis, a main problem is to guarantee its invertibility
and to be able to determine an inverse synthesis filter bank.
As the analysis scheme corresponds to a redundant decomposition,
there is no unique inverse filter bank and some of the
solutions can lead to artifacts in textured image filtering applications.
In this paper, the flexibility in the choice of the inverse
filter bank is exploited to find the best-localized impulse
responses. The design is performed by solving a constrained
optimization problem which is reformulated in a smaller dimensional
space. Application to seismic data clearly shows
the improvements brought by the optimization process.
Keywords: FIR digital filters, Transforms, Redundancy,
Optimization methods, Seismic signal processing
Inversion de bancs de filtres M-bandes
sur-échantillonnés
Jérome Gauthier, Laurent Duval
Journée nationale sur les logiciels de modélisation
et de calcul scientifique (LMCS 2006), Paris-La Défense,
France, November (novembre) 2006 [conference]
Signals and images in industrial applications are often subject to strong disturbances and thus require robust
methods for their analysis. Since these data are often non-stationary, time-scale or time-frequency tools have
demonstrated effectiveness in their handling. More specifically, wavelet transforms and other filter bank generalizations
are particularly suitable, due to their discrete implementation. We have recently investigated a specific
family of filter banks, the M-band dual-tree wavelet, which provides state of the art performance for image
restoration. It generalizes an Hilbert pair based decomposition structure, first proposed by N. Kingsbury and
further investigated by I. Selesnick. In this work, we apply this frame decomposition to the analysis of two
examples of signals and images in an industrial context: detection of structures and noises in geophysical images
and the comparison of direct and indirect measurements resulting from engine combustion.
Keywords: M-band wavelets, Hilbert transform, Dual-tree, Image denoising, Direction analysis.
In a previous work, we proposed a relatively simple method to build
non separable perfect reconstruction oversampled lapped transforms.
The main drawback of this method was that the redundancy factor
was constrained to be equal to the overlapping one. This constitutes
a strong limitation for applications such as seismic processing involving
three-dimensional data sets. The memory requirements may
indeed become hard to meet if the redundancy is not reduced. In
this paper, we propose an approach to guarantee that a given lapped
transform is invertible by a finite length filter bank. We show how to
compute a corresponding synthesis filter bank. The proposed analysis/
synthesis filter bank system is applied to directional filtering of
noisy three-dimensional seismic data.
Surface wave attenuation is a difficult problem to address
in foothills areas due to the high variability of their
typology. Such recorded events can indeed be non linear
and even mimic reflection hyperbolas.
We present two innovative approaches that exploit the
combination of different criteria so as to discriminate be-
tween effective signal and noise. The first one makes
use of both apparent velocity and polarisation. Its
ability to detect noise is demonstrated on a synthetic
multi-component data set inspired from South American
foothills. The second one combines apparent velocity and
a decomposition on different time and space scales. Im-
provements over classical FK filtering are shown on a sin-
gle component real data set from Canadian foothills
In this work, we study the properties of an additive noise undergoing a dual-tree M-band wavelet analysis. We express the relationships governing noise coefficients both in the primal and the dual tree. The knowlegde of the noise statistical properties is particularly useful for the design of efficient denoising methods in the framework of a dual-tree wavelet analysis. Our main contribution consists in the computation of the resulting cross-correlation functions for several M-band wavelet families. More specifically, we show that pairwise coefficients, from the primal and the dual-tree resulting from a white noise decomposition, are uncorrelated. Yet, there exists a significant local correlation, whose extent depends on the choice of the wavelet pair.
Seismic data analysis and filtering with dual-tree
M-band wavelets
Laurent Duval, Caroline Chaux, Jean-Christophe Pesquet and Karine
Broto,
SIAM GS 2005, SIAM Conference on Mathematical and Computational Issues in the
Geosciences, Avignon, France, June 2005 [conference]
Seismic data analysis with a dual-tree M-band wavelet
transform
Caroline Chaux, Laurent Duval and Jean-Christophe Pesquet
67th European Assoc. of Geophysicists and Engineers (EAGE 2005)
Conference, Madrid, Spain, June 2005 [conference]
2D
Dual-Tree M-band Wavelet Decomposition ,
Caroline Chaux (winner of the Student Paper Contest),
Laurent Duval and Jean-Christophe Pesquet,
International Conference on Acoutics, Speech and Signal Processing
(ICASSP 2005), Philadelphia, USA, March 2005 [conference]
Evaluation of comprehensive two-dimensional gas
chromatography (GCxGC) for the detailed characterization of complex
hydrocarbon mixtures
Colombe Vendeuvre, Fabrice Bertoncini, Laurent Duval, S. Penet, F.
Monot, Franck Haeseler, D. Thiébaut, M.-C. Hennion, ASMS 2004
27th International Symposium on Capillary Chromatography Riva del
Garda, Italy, May-June 2004 [conference]
Analysis of products issued from paraffins dehydrogenation
by fast GC/MS, HRGC/MS and comprehensive GCxGC
Nancy Leymarie, Colombe Vendeuvre, Laurent Duval, Fabrice
Bertoncini, Christophe Roullet, Frédérique Prigent,
Nadine Bucher, Stéphane Morin
52nd American Society on Mass Spectrometry Conference on Mass
Spectrometry and Allied Topics, Nashville, USA-TN, May 2004
(ASMS
2004)
Geophysical signal denoising using Multiple Wavelet
Stacking
Laurent Duval
65th European Assoc. of Geophysicists and Engineers (EAGE)
Conference, Stavanger, Norway, June 2003 (EAGE 2003)
Seismic data compression using GULLOTS
Laurent Duval and Takayuki Nagai
International Conference on Acoustics, Speech and Signal Processing
(ICASSP), Salt Lake City, USA, May 2001
GenLOT optimization techniques for seismic data
compression
Laurent Duval and Van Bui-Tran and Nguyen, T. Q. and Tran, T.
D.
International Conference on Acoustics, Speech and Signal Processing
(ICASSP), p. 2111-2114, Istanbul, Turkey, June 2000
Compression de données sismiques par ondelettes et
GenLOT
Laurent Duval, Van Bui-Tran
Réunion des théoriciens des circuits de langue
française (RTCLF), p. 23-24, Metz, France, Oct. 1999
Some new results about dual-tree wavelet decompositions
Jean-Christophe Pesquet, Université de Marne la
Vallée
Jean-Christophe Pesquet, Caroline Chaux, Laurent Duval
Wavelets and Applications Semester 2006, 13 April 2006, EPFL
(Wave 2006)
Satellite image restoration using an M-band dual-tree
wavelet analysis
Caroline Chaux, Laurent Duval, Amel Benazza-Benyahia,
Jean-Chistophe Pesquet
Workshop "Geometrical Transforms for Image Processing - Application
to Satellite Image restoration and Compression", (workshop) Toulouse, France, November
2005
Débruitage d'images par analyse en ondelettes
M-bandes en arbre dual (Image denoising via dual-tree M-band
wavelet analysis)
Caroline Chaux, Jean-Christophe Pesquet, Laurent Duval
Workshop "Contenu Informatif des Images Numériques", 25-26
novembre 2004, ENS de Cachan, Paris (CIIN 2004)
Second poster presentation award to Aurélie Pirayre et al., "Incorporating structural a priori in Gene Regulatory Network Inference using Graph cuts" [Poster, Awarded 2nd best poster], European Student Council Symposium 2014 (ESCS'14), Strasbourg, France
Copyright: This material is presented to ensure timely dissemination of
scholarly and technical work. Copyright and all rights therein are retained by
authors or by other copyright holders. All persons copying this information are
expected to adhere to the terms and constraints invoked by each author's
copyright. In most cases, these works may not be reposted without the explicit
permission of the copyright holder.
Copyright notice for IEEE publications: (c)20xx IEEE. Personal use of this
material is permitted. However, permission to reprint/republish this material
for advertising or promotional purposes or for creating new collective works
for resale or redistribution to servers or lists, or to reuse any copyrighted
component of this work in other works must be obtained from the IEEE.



{kind=link}